 |
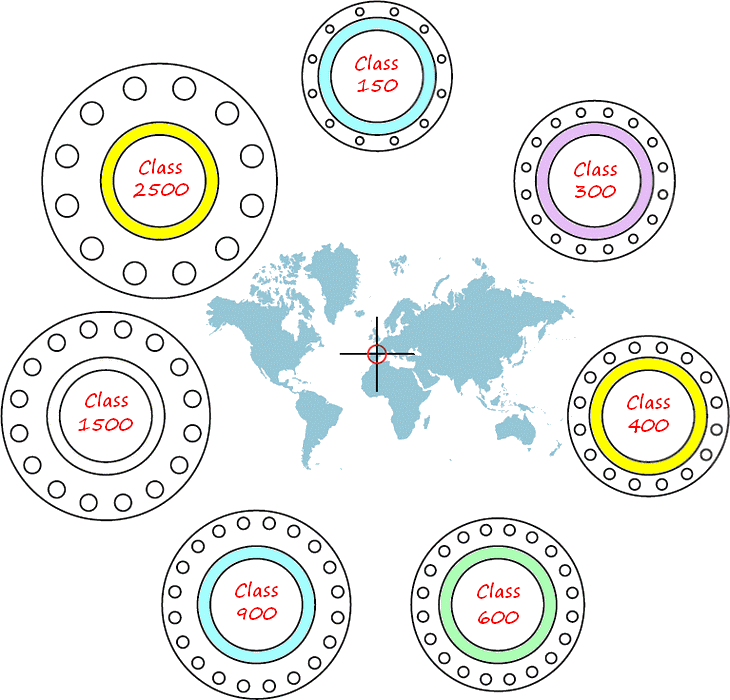
Pressure Classes of Flanges |
Forged steel flanges ASME B16.5 are made in seven primary Pressure Classes..
150
300
400
600
900
1500
2500
The concept of flange ratings likes clearly. A Class 300 flange can handle more pressure than a Class 150 flange, because a Class 300 flange are constructed with more metal and can withstand more pressure. However, there are a number of factors that can impact the pressure capability of a flange.
Pressure Rating Designation
The Pressure Rating for flanges will be given in Classes.
Class, followed by a dimensionless number, is the designation for pressure-temperature ratings as follows.. Class 150 300 400 600 900 1500 2500.
Different names are used to indicate a Pressure Class. For example.. 150 Lb, 150 Lbs, 150# or Class 150, all are means the same.
But there is only one correct indication, and that is Pressure Class, according to ASME B16.5. (the pressure rating is a dimensionless number).
Example of Pressure Rating
Flanges can withstand different pressures at different temperatures. As temperature increases, the pressure rating of the flange decreases. For example, a Class 150 flange is rated to approximately 270 PSIG at ambient conditions, 180 PSIG at approximately 400°F, 150 PSIG at approximately 600°F, and 75 PSIG at approximately 800°F.
In other words, when the pressure goes down, the temperature goes up and vice versa. Additional factors are that flanges can be constructed from different materials, such as stainless steel, cast and ductile iron, carbon steel etc.. Each material have different pressure ratings.
Below an example of a flange NPS 12 with the several pressure classes. As you can see, inner diameter and diameter of the raised face at all the same; but outside diameter, bolt circle and diameter of bolt holes become larger in each higher pressure class.
The number and diameters (mm) of the bolt holes are..
Class 150▸ 12 x 25.4
Class 300▸ 16 x 28.6
Class 400▸ 16 x 34.9
Class 600▸ 20 x 34.9
Class 900▸ 20 x 38.1
Class 1500▸ 16 x 54
Class 2500▸ 12 x 73
Pressure-Temperature Ratings - Example
Pressure-temperature ratings are maximum allowable working gage pressures in bar units at the temperatures in degrees celsius. For intermediate temperatures, linear interpolation is permitted. Interpolation between class designations is not permitted.
Pressure-temperature ratings apply to flanged joints that conform to the limitations on bolting and on gaskets, which are made up in accordance with good practice for alignment and assembly. Use of these ratings for flanged joints not conforming to these limitations is the responsibility of the user.
The temperature shown for a corresponding pressure rating is the temperature of the pressure-containing shell of the component. In general, this temperature is the same as that of the contained fluid. Use of a pressure rating corresponding to a temperature other than that of the contained fluid is the responsibility of the user, subject to the requirements of applicable codes and regulations. For any temperature below -29°C, the rating shall be no greater than the rating shown for -29°C.
As an example, below you will find two tables with material groups ASTM, and two other tables with flange pressure-temperature ratings for those ASTM materials ASME B16.5.
| ASTM Group 2-1.1 Materials |
|||
| Nominal Designation |
Forgings | Castings | Plates |
| C-Si | A105(1) | A216 Gr.WCB (1) |
A515 Gr.70 (1) |
| C Mn Si | A350 Gr.LF2 (1) |
A516 Gr.70 (1), (2) |
|
| C Mn Si V | A350 Gr.LF6 Cl 1 (3) |
A537 Cl.1 (4) |
|
| 3.1/2Ni | A350 Gr.LF3 |
||
|
Notes..
|
|||
| ASTM Group 2-2.3 Materials |
|||
| Nominal Designation |
Forgings | Castings | Plates |
| 16Cr 12Ni 2Mo | A182 Gr.F316L |
A240 Gr.316L |
|
| 18Cr 13Ni 3Mo | A182 Gr.F317L |
||
| 18Cr 8Ni | A182 Gr.F304L (1) |
A240 Gr.304L (1) |
|
|
Note..
|
|||
|
Pressure-Temperature Ratings for ASTM Group 2-1.1 Materials |
|||||||
| Temp -29 °C |
150 | 300 | 400 | 600 | 900 | 1500 | 2500 |
| 38 | 19.6 | 51.1 | 68.1 | 102.1 | 153.2 | 255.3 | 425.5 |
| 50 | 19.2 | 50.1 | 66.8 | 100.2 | 150.4 | 250.6 | 417.7 |
| 100 | 17.7 | 46.6 | 62.1 | 93.2 | 139.8 | 233 | 388.3 |
| 150 | 15.8 | 45.1 | 60.1 | 90.2 | 135.2 | 225.4 | 375.6 |
| 200 | 13.8 | 43.8 | 58.4 | 87.6 | 131.4 | 219 | 365 |
| 250 | 12.1 | 41.9 | 55.9 | 83.9 | 125.8 | 209.7 | 349.5 |
| 300 | 10.2 | 39.8 | 53.1 | 79.6 | 119.5 | 199.1 | 331.8 |
| 325 | 9.3 | 38.7 | 51.6 | 77.4 | 116.1 | 193.6 | 322.6 |
| 350 | 8.4 | 37.6 | 50.1 | 75.1 | 112.7 | 187.8 | 313 |
| 375 | 7.4 | 36.4 | 48.5 | 72.7 | 109.1 | 181.8 | 303.1 |
| 400 | 6.5 | 34.7 | 46.3 | 69.4 | 104.2 | 173.6 | 289.3 |
| 425 | 5.5 | 28.8 | 38.4 | 57.5 | 86.3 | 143.8 | 239.7 |
| 450 | 4.6 | 23 | 30.7 | 46 | 69 | 115 | 191.7 |
| 475 | 3.7 | 17.4 | 23.2 | 34.9 | 52.3 | 87.2 | 145.3 |
| 500 | 2.8 | 11.8 | 15.7 | 23.5 | 35.3 | 58.8 | 97.9 |
| 538 | 1.4 | 5.9 | 7.9 | 11.8 | 17.7 | 29.5 | 49.2 |
|
Pressure-Temperature Ratings for ASTM Group 2-2.3 Materials |
|||||||
| Temp -29 °C |
150 | 300 | 400 | 600 | 900 | 1500 | 2500 |
| 38 | 15.9 | 41.4 | 55.2 | 82.7 | 124.1 | 206.8 | 344.7 |
| 50 | 15.3 | 40 | 53.4 | 80 | 120.1 | 200.1 | 333.5 |
| 100 | 13.3 | 34.8 | 46.4 | 69.6 | 104.4 | 173.9 | 289.9 |
| 150 | 12 | 31.4 | 41.9 | 62.8 | 94.2 | 157 | 261.6 |
| 200 | 11.2 | 29.2 | 38.9 | 58.3 | 87.5 | 145.8 | 243 |
| 250 | 10.5 | 27.5 | 36.6 | 54.9 | 82.4 | 137.3 | 228.9 |
| 300 | 10 | 26.1 | 34.8 | 52.1 | 78.2 | 130.3 | 217.2 |
| 325 | 9.3 | 25.5 | 34 | 51 | 76.4 | 127.4 | 212.3 |
| 350 | 8.4 | 25.1 | 33.4 | 50.1 | 75.2 | 125.4 | 208.9 |
| 375 | 7.4 | 24.8 | 33 | 49.5 | 74.3 | 123.8 | 206.3 |
| 400 | 6.5 | 24.3 | 32.4 | 48.6 | 72.9 | 121.5 | 202.5 |
| 425 | 5.5 | 23.9 | 31.8 | 47.7 | 71.6 | 119.3 | 198.8 |
| 450 | 4.6 | 23.4 | 31.2 | 46.8 | 70.2 | 117.1 | 195.1 |
FULL LIST OF ASTM MATERIAL SPECIFICATIONS
Remark(s) of the Author...
150lb - 150lbs - 150# - Class 150
LB is the origin of the Latin word libra (weighing scale), and describes a Roman unit of mass similar to a pound.
The full expression was librapondo, and we have invented acronyms such as..
lb = one pound, lbs = more pounds, # = Abbreviation for pound
Text below is from www.worldwidewords.org copyright © of Michael Quinion
The form lb is actually an abbreviation of the Latin word libra, which could mean a pound, itself a shortened form of the full expression, libra pondo, "pound weight". The second word of this phrase, by the way, is the origin of the English pound.
You will also know Libra as the astrological sign, the seventh sign of the zodiac. In classical times that name was given to rather an uninspiring constellation, with no particularly bright stars in it. It was thought to represent scales or a balance, the main sense of libra in Latin, which is why it is often accompanied by the image of a pair of scales.
Libra for a pound is first found in English in the late fourteenth century, almost at the same time as lb started to be used. Strictly speaking again, this was the Roman pound of 12 ounces, not the more modern one of 16. And just to consolidate my reputation for careful description, modern metrologists, scientists who study units of measurements, would prefer that we don't use lbs at all; in scientific work, all units are singular.
Incidentally, another abbreviation for libra became the standard symbol for the British pound in the monetary sense. In modern times it is usually written £, an ornate form of L in which a pair of cross-strokes (often just one these days) were the way that a medieval scribe marked an abbreviation. The link between the two senses of pound, weight and money, is that in England a thousand years ago a pound in money was equivalent to the value of a pound of silver.
Related Post(s)
Flanges - ASME B16.5 - Inch Dimensions - Weld Neck/Stud Bolts Class 150 to Class 2500...